Experimental Evaluation of RAG Systems (FYP)
An in-depth Final Year Project evaluating Retrieval-Augmented Generation (RAG) systems.
A Final Year Project that evaluates the performance of Retrieval-Augmented Generation (RAG) systems against stand-alone LLMs. This study evaluates various LLMs (Llama3, Gemma2, GPT-4o Mini) across different RAG paradigms (Naive vs. Advanced) on standard datasets like SQuAD and MS MARCO, focusing on performance metrics and hallucination reduction.
Why RAG is essential for LLM-powered Knowledge Bases
The rapid adoption of Large Language Models (LLMs) for information retrieval is incredibly suprising as their inherent unreliability when dealing with factual or time-sensitive data. In the context of building a Personal Knowledge Base (PKB), where integrity and accuracy are of absolute importance, however hallucinations and outdated knowledge still renders standalone LLMs fundamentally unfit for many applications.
my Bachelor’s thesis addressed this challenge directly by evaluating Retrieval-Augmented Generation (RAG) as a solution to enhance the factual accuracy and viability of LLMs for PKB applications. the core finding shows that RAG is not merely an improvement but also a architectural necessity for trustworthy AI-driven knowledge management and applications.
RAG impact on Factual Accuracy of LLM Output.
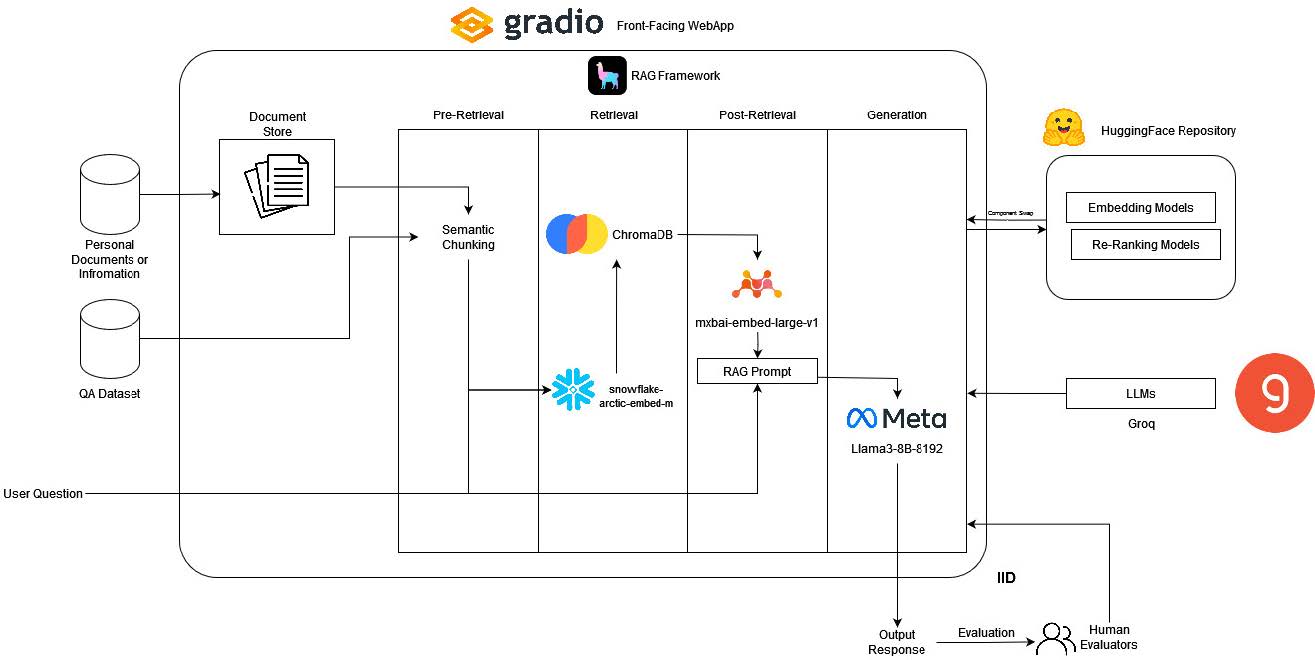
We 1 tested normal, standalone large language models (LLM)s versus the same LLM when its answers are grounded in an external knowledge base via RAG. the primary LLM for the main tests was llama 3 8b, which is a great LLM for its size, but it’s still a “closed-book” learner — it can only output from it’s training sessions.
The project used a structured evaluation comparing the performance of a standalone LLM (Llama 3 8B) against two RAG-enabled pipelines (Naïve RAG and Advanced RAG)2 on a curated Question-Answering (QA) dataset derived from the industry benchmarks MS MARCO and SQUAD.
the results demonstrated a dramatic shift in reliability:
- No RAG Baseline: The standard Llama 3 8B, relying solely on its parametric knowledge, achieved a poor $57.81\%$ factual accuracy.
- Advanced RAG Performance: By incorporating external, non-parametric knowledge retrieved from the knowledge base, the Advanced RAG solution achieved $87.5\%$ factual accuracy.
This represents an absolute increase of $29.69$ percentage points over its own baseline model, and a measured improvement of $34-50\%$ over popular conventional LLMs tested, including GPT-4o-mini and Mixtral-8x7b. the key takeaway here is that RAG effectively grounds the LLM’s generation process, significantly mitigating the occurrence of fact-conflicting hallucinations.
| Method | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| Advanced RAG | 0.867 | 0.386 | 0.696 | 0.442 |
| Naïve RAG | 0.836 | 0.359 | 0.692 | 0.416 |
| No RAG (Llama 3 8B) | 0.578 | 0.239 | 0.396 | 0.266 |
| GPT4o-mini | 0.625 | 0.130 | 0.438 | 0.182 |
| Mixtral-8x7b | 0.609 | 0.077 | 0.442 | 0.117 |
further analysis using token-level metrics confirmed the Advanced RAG as the superior performer, demonstrating that it produces answers of higher quality and fidelity to the target ground truth, beyond simple binary accuracy.
The Practical fix for outdated / not up to date knowledge
One of the intrinsic challenges for LLMs is their reliance on static training data, leading to inevitable obsolescence over time.
the ability of RAG to inject new facts also solves the outdated knowledge problem. i did a quick experiment using a PDF of maybank’s financial info dated november 2024—well after llama 3’s public march 2023 cutoff.
the standalone LLM answered with disclaimers or old, incorrect values (like the wrong ceo) . the RAG-enabled version, however, successfully provided the up-to-date rm 10.40 stock price and the current rm 6.96b quarterly revenue for jun 2024, directly from the embedded document . it’s basically a live knowledge update for the LLM, on the fly, without the cost and complexity of fine-tuning or re-training the whole model.
Architectural efficiency and Accessibility
a big barrier for us self-studiers and hobbyists is hardware. i was working with an NVIDIA GTX 1070 with only 8gb of vram . running a decent 7b-8b parameter model locally is a headache, even with quantization tricks like llama.cpp.
Groqcloud was the answer. instead of relying on GPUs, groq uses specialized language processing units (lpus) . to give you an idea of the speed difference, my RAG solution on groq’s hardware hit an average of 259.86 tokens per second (tps) in performance tests . compare that to top-end consumer gpus like the rtx 4090, which manages about 54.34 tps on the same model—groq gave me nearly five times the throughput.
this accessibility is huge. it meant i could prototype with top-tier performance without needing a 10,000$ machine. it democratizes the capability to run high-performance AI systems, making RAG a genuinely practical solution for independent developers.
Limitations and Future Work
the Advanced RAG architecture, incorporating Semantic Chunking and a Reranker, proved superior in this open-domain QA setting. however, it’s important to acknowledge that iterative cycles, while generally beneficial, don’t guarantee universally better results. The retrieval component plays a large factor in the success of the pipeline. Hence all these new components (reranker, retrieval) that has been added need to be measured, logged and evaluated for consistency and accuracy.
future enhancements could focus on more advanced RAG modalities, such as implementing Knowledge Graph RAG (KG-RAG), which utilizes explicit semantic relationships between data points, or incorporating multi-modal LLMs for processing complex inputs like images and tables to reduce information loss during the ingestion pipeline or even HyDE, Hypothetical Document Embeddings.
the research establishes RAG as the definitive architectural choice for integrating reliable AI into personal knowledge management systems.
Footnotes
-
I like to “We” instead of “I”; I’d like to think this isn’t schizophrenia, just habit. ↩
-
These architectures are explicitly named as such in Gao et al., 2023 based on their components — Naïve being a simple retrieve-and-generate loop, while Advanced adds pre-retrieval and post-retrieval optimizations like reranking. This is probably the single most asked question about this project. ↩